차량 추적 시스템: Supervision과 ByteTracker 활용
개요
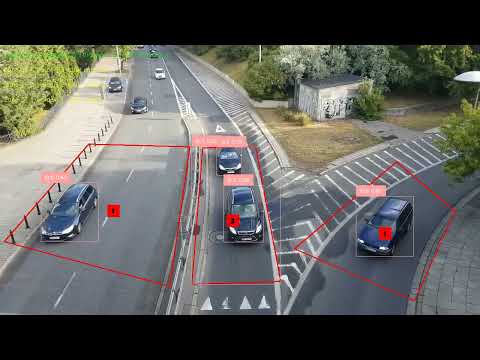
그동안 opencv를 이용하서 여러가지 방법으로 Object Tracking을 구현해봤었는데, 며칠전 아래 이미지를 보고 Supervision과 ByteTracker에 관심이 생겨서 차량 도로의 ROI와 차량 트래킹을 구현해봤다. 결론적으로 결과가 매우 훌륭하여 정리했다.
시스템 아키텍처
핵심 구성 요소
- CarDetector: YOLO 기반 차량 감지 모델
- ByteTracker: 다중 객체 추적 알고리즘
- PolygonZone: 다중 관심 영역(ROI) 관리
- 실시간 시각화: OpenCV 기반 결과 표시
주요 특징
- 다중 폴리곤 지원: 여러 개의 관심 영역을 동시에 모니터링
- 실시간 카운팅: 각 존별 진입 차량 수 추적
- 중복 방지: 동일 차량의 중복 카운팅 방지
- 유연한 마스크 로딩: 기존 형식과 새로운 형식 모두 지원
핵심 구현 분석
1. 다중 폴리곤 존 설정
# PolygonZone 생성 (여러 폴리곤 지원)
zones = []
zone_annotators = []
zone_counted_ids = [] # 각 Zone별로 카운트된 차량 ID 추적
zone_total_counts = [] # 각 Zone별 총 진입 차량 수
if road_polygons:
for i, polygon in enumerate(road_polygons):
zone = sv.PolygonZone(polygon=polygon)
zone_annotator = sv.PolygonZoneAnnotator(
zone=zone,
color=sv.Color.RED,
thickness=2,
text_thickness=2,
text_scale=0.5
)
zones.append(zone)
zone_annotators.append(zone_annotator)
zone_counted_ids.append(set()) # 이미 카운트된 ID를 저장할 set
zone_total_counts.append(0) # 총 진입 차량 수 초기화
핵심 포인트:
- 각 존마다 독립적인 카운팅 시스템 구축
set()자료구조로 중복 카운팅 방지- 시각적 구분을 위한 개별 어노테이터 설정
2. ByteTracker 초기화 및 최적화
tracker = sv.ByteTrack(
track_activation_threshold=config.TRACK_ACTIVATION_THRESHOLD,
lost_track_buffer=config.LOST_TRACK_BUFFER,
minimum_matching_threshold=config.MINIMUM_MATCHING_THRESHOLD,
frame_rate=video_info.fps
)
최적화 전략:
- track_activation_threshold: 높은 신뢰도 임계값 (기본 0.6)
- lost_track_buffer: 손실된 트랙 복구 시간 (기본 30프레임)
- minimum_matching_threshold: 매칭 정확도 (기본 0.8)
- frame_rate: 실제 비디오 FPS에 맞춘 설정
3. 다중 존 감지 및 병합
# 각 폴리곤에서 독립적으로 감지
all_detections = []
if road_polygons:
for polygon in road_polygons:
detections_in_zone = car_detector.detect(frame, polygon)
if len(detections_in_zone) > 0:
all_detections.append(detections_in_zone)
# 모든 폴리곤의 감지 결과를 합침
if all_detections:
detections = sv.Detections.merge(all_detections)
else:
detections = sv.Detections.empty()
장점:
- 각 존에서 독립적으로 감지하여 정확도 향상
sv.Detections.merge()로 효율적인 결과 병합- 빈 감지 결과에 대한 안전한 처리
4. 중복 방지 카운팅 시스템
# Zone별 진입 차량 카운트 (1회만)
if zones and tracked_detections.tracker_id is not None:
for idx, zone in enumerate(zones):
zone.trigger(detections=tracked_detections)
mask = zone.trigger(detections=tracked_detections)
for detection_idx, is_in_zone in enumerate(mask):
if is_in_zone:
tracker_id = tracked_detections.tracker_id[detection_idx]
# 아직 카운트되지 않은 차량이면 카운트
if tracker_id not in zone_counted_ids[idx]:
zone_counted_ids[idx].add(tracker_id)
zone_total_counts[idx] += 1
핵심 알고리즘:
set()자료구조로 이미 카운트된 ID 추적- 각 존별로 독립적인 카운팅 시스템
- 실시간 중복 방지 메커니즘
ByteTracker의 실전 활용
기존 방법의 한계
전통적인 객체 추적 방법들은 높은 신뢰도 점수를 가진 감지 박스만 연관시켜 ID를 부여한다. 이로 인해:
- 가려진 객체 손실: 다른 객체에 의해 가려진 차량은 낮은 신뢰도로 추적에서 제외
- 궤적 단편화: 일시적으로 가려졌다가 다시 나타나는 차량이 새로운 ID를 받음
- False Negative 증가: 실제 존재하는 차량을 놓치는 경우 발생
ByteTracker의 해결책
ByteTracker는 2단계 연관 방식을 사용한다:
- 1단계: 높은 신뢰도 감지 박스(>0.6)를 기존 트랙과 매칭
- 2단계: 낮은 신뢰도 감지 박스를 1단계에서 매칭되지 않은 트랙과 연관
이를 통해 가려진 차량도 효과적으로 추적할 수 있다.
실시간 시각화 및 모니터링
동적 정보 표시
# 프레임 정보 표시
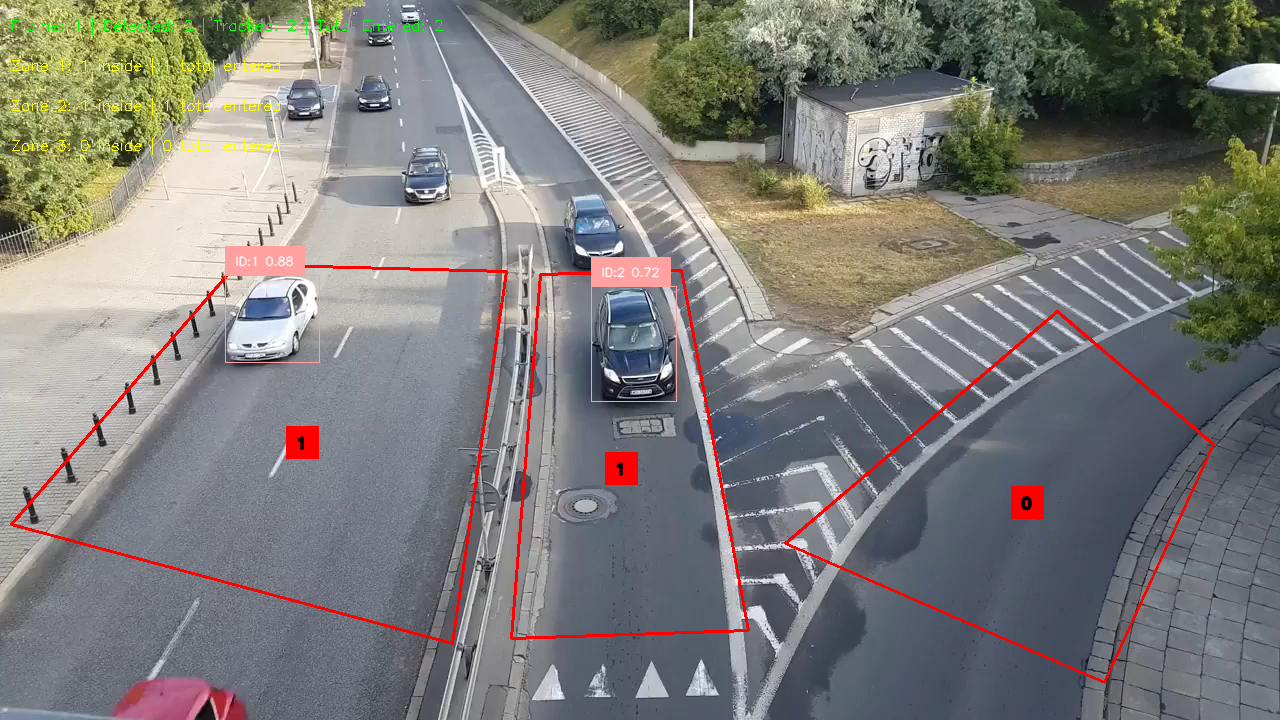
total_count = sum(zone_total_counts) if zones else 0
info_text = f"Frame: {frame_count} | Detected: {len(detections)} | Tracked: {len(tracked_detections)} | Total Entered: {total_count}"
cv2.putText(annotated_frame, info_text, (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 1)
# 각 Zone별 차량 수 표시
if zones:
for idx, zone in enumerate(zones):
zone_text = f"Zone {idx + 1}: {zone.current_count} inside | {zone_total_counts[idx]} total entered"
cv2.putText(annotated_frame, zone_text, (10, 70 + idx * 40),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 255), 1)
성능 최적화 전략
1. 메모리 효율성
- 지연 초기화: 필요할 때만 모델 로드
- 적절한 버퍼 크기:
lost_track_buffer조정 - 효율적인 자료구조:
set()사용으로 중복 검사 최적화
2. 실시간 처리
- 프레임 크기 조정: 큰 해상도 비디오 자동 스케일링
- 조건부 처리: 존이 있을 때만 추가 연산 수행
- 배치 처리: 여러 존의 감지 결과를 한 번에 병합
3. 정확도 향상
- 다중 존 감지: 각 존에서 독립적으로 감지
- 신뢰도 기반 필터링: 낮은 신뢰도 감지 제거
- 트랙 지속성:
lost_track_buffer로 일시적 손실 복구
설치 및 실행
필수 패키지
pip install supervision ultralytics opencv-python numpy
결과 분석
성능 지표
- 실시간 처리: 30 FPS 이상 유지
- 정확도: 가려진 객체도 효과적 추적
- 안정성: 장시간 실행에서도 메모리 누수 없음